

IaC (or “Infrastructure as Code”) is an IT management style all members of the technical world have to deal with because working in code vs. manual processes, as IaC entails, can make processes more efficient. Everyone who works with IaC, though, has to sometimes face a “drift,” which is when our configuration/source code does not describe the cloud resources as it should. Somebody manually changed the CPU count, attached the IP address, or took another action that caused the configuration to malfunction because they forgot that we don’t do that by hand anymore. We have IaC.
This may not seem like a big deal, and oftentimes the resulting problem isn’t. Except for when it is.
We use the concept of IaC so that we can have a single source of “truth,” or an established set of standards that we can go back to and rely upon without fail. If we make manual changes in the console, where is the truth now? It’s tampered with; it’s bent; it’s been compromised. Whatever might have been the reasons for the manual change, most of the time it is not worth it because all of a sudden we have deviated from this shared truth that makes our processes work and that can result in additional internal problems and colleagues no longer being on the same page as they try to root out where things went wrong.
The Never-ending Drift Mitigation Process
Now, when we establish there is a drift problem, what solutions can we use? Well, at ShipMonk, we start with the most basic investigations first before looking into complex ones; oftentimes, searching in obvious places can lead to faster cleanup. For example, every morning, we check the configuration of each Terragrunt folder, and if there were any changes we send the discovered info to our specialists in their Slack group channel. Those who are on-call will take the information and proactively mitigate detected drifts.
Here is an example of the kind of data we analyze in these drift cases:
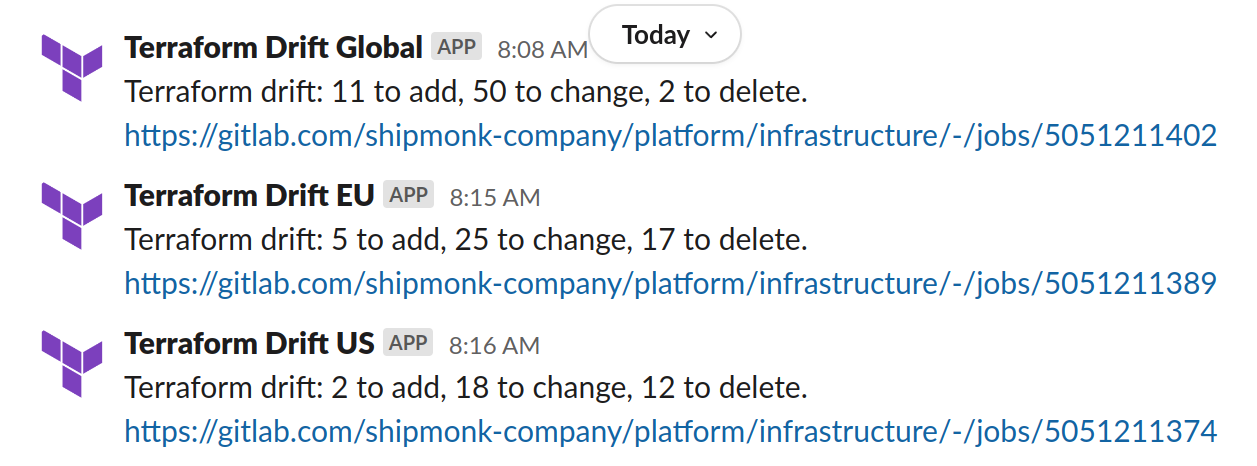
If only it were that simple every time. Our on-call engineers are talented, but they don’t always have time to instantly mitigate every slight drift caused by a colleague deviating from IaC; they have their own high-level duties to see to. Therefore, we don’t believe in passing off drift removals to on-call engineers as a foolproof solution. They may not get to them quickly, and frankly, that’s not their main responsibility. The best tactic is figuring out how to notify the people responsible for causing the drifts so they know to remove the errors themselves.
Cloud Auditing to the Rescue
There are various cloud-auditing tools out there. Cloudflare has audit logs, which are accessible by API. Datadog has the same. Using these cloud audits, you can check for each drifted resource in the audit log and notify the responsible party once there is a mention of a user making any change to that resource. Most of our resources are in the AWS cloud, that’s why it is our priority for drift checking. Querying the AWS API with cloud audit logs can also be done by SDK call to CloudTrail:
func getCloudTrailEventsByID(id string, arn string) []Event {
aws_region := strings.Split(arn, ":")[3]
if aws_region == "" {
aws_region = "us-east-1"
}
sess := session.Must(session.NewSession(&aws.Config{
Region: aws.String(aws_region),
}))
ct := cloudtrail.New(sess)
input := &cloudtrail.LookupEventsInput{
LookupAttributes: []*cloudtrail.LookupAttribute{
{
AttributeKey: aws.String("ResourceName"),
AttributeValue: aws.String(id),
},
},
MaxResults: aws.Int64(1),
}
result, err := ct.LookupEvents(input)
if err != nil {
log.Error(err)
}
var events []Event
for _, evt := range result.Events {
var event Event
json.Unmarshal([]byte(*evt.CloudTrailEvent), &event)
events = append(events, event)
}
return events
}We only need one record because we are looking for the last resource mentioned. You can get confused by the id parameter, which is used as ResourceName, but don’t let that fool you; that’s just the way Terraform identifies the resources in the state output. Everything else is just a code from documentation.
The output of the call of CloudTrail API can be presented as JSON in a similar form:
{
"eventVersion": "1.08",
"userIdentity": {
"type": "AssumedRole",
"principalId": "...:martin_beranek",
"arn": "arn:aws:sts::...:assumed-role/shipmonk_administrator/martin_beranek",
"sessionContext": {
"sessionIssuer": {
"type": "Role",
...
"userName": "shipmonk_administrator"
},
...
}
},
"eventTime": "2023-09-08T10:11:40Z",
"eventSource": "rds.amazonaws.com",
"eventName": "AddRoleToDBCluster",
...
"requestParameters": {
"dBClusterIdentifier": "production-aurora-80-cluster",
"roleArn": "arn:aws:iam::...:role/RDSLoadFromS3"
},
"responseElements": null,
"readOnly": false,
"eventType": "AwsApiCall",
"managementEvent": true,
"recipientAccountId": ..."
}The JSON above representing CloudTrail event shows that I changed the Aurora Cluster role assignment. I, as always, forgot to put the change into our Terraform configuration code. Therefore, I should receive a notification to fix the drift.
To filter relevant events to the appropriate users, you have to have a single username for each contributor to the services in each of the platforms your users work in (i.e. Slack, AWS, Datadog etc.). If you are using SSO with your Google account, you are done. Your identity is closely tight to your email and it’s not easy to use anything else. That can be difficult to resolve for other login approaches. You might end up with a public user registry containing users’ usernames mapped to their emails (LDAP, …). At ShipMonk, the naming convention we utilize for simplified communication is name_surname. For the sake of consistency, that same naming logic is applied across all platforms we work with, including Slack, so we can map and connect AWS users to Slack users easily.
How Do We Get Drifted Resources from Terraform?
To get the list of the resources, you can use terraform plan -json command. Resources which are drifted are under type planned_change. There are also resource_drift resources types, but those do not have to be planned for a change. In case you are interested, check Terraform’s internal documentation.
Here is an example line of the output from the plan command:
{
"@level": "info",
"@message": "module.prod-aurora.aws_rds_cluster.aurora: Plan to update",
"@module": "terraform.ui",
"@timestamp": "2023-09-10T17:48:29.045598Z",
"change": {
"resource": {
"addr": "module.prod-aurora.aws_rds_cluster.aurora",
"module": "module.prod-aurora",
"resource": "aws_rds_cluster.aurora",
"implied_provider": "aws",
"resource_type": "aws_rds_cluster",
"resource_name": "aurora",
"resource_key": null
},
"action": "update"
},
"type": "planned_change"
}To query the CloudTrail, you must parse the resource’s id from the state. The line above from the plan does not give you that. Hence, you can execute terraform show -json, which displays every item Terraform manages in JSON form. Here is an example of an item of an Aurora resource which is referenced in the line above:
{
"address": "module.prod-aurora.aws_rds_cluster.aurora",
"mode": "managed",
"type": "aws_rds_cluster",
"name": "aurora",
"arn": "arn:aws:rds:us-east-1:824679639808:cluster:production-aurora-80-cluster",
"availability_zones": [
"us-east-1a",
"us-east-1b",
"us-east-1d"
],
"id": "production-aurora-80-cluster",
...Now we have all the information we need. The resource name to be used in CloudTrail is the id from the Terraform state file. The region to be queried is part of the ARN of that resource, which is also sent as a parameter of our getCloudTrailEventsByID function.
User Notification
After a discussion within our infrastructure team, we decided the best way to proceed is to receive the requested information in a private message from the Slack bot. That’s a bot used for custom reminders, responses, and whatever is needed at the moment. Ultimately, the message format for us looks something like this:

Summary
Through analysis and collaboration, we’ve discovered that personal messages help engineers resolve drifts much faster. Once you set up a schedule and send drift notifications every day, users start to anticipate and be on the lookout, which in turn tends to lead to drifts being fixed right away. After all, nobody wants to be the one who is making life difficult for others in the team.
As a bonus, along the way to figuring out how to best resolve drifts, we also noticed a few other people making changes in the AWS. Those are our colleagues with admin privileges who sometimes use those privileges to speed up critical bug fixes but may not always update the whole team about those actions. Now that we have the nifty notifications tools, we no longer have to worry about them forgetting to tell us about any admin changes that were made that may affect us, though. We get notified about those too!
Overall, this is a good, multi-beneficial result for a tool that compares a Terraform state with the upstream audit.
Anyway, like they say, like & subscribe. If you are interested in the POC code, it could be located at github.