

When it comes to the cloud, the most frustrating area can be the NAT gateway. I have a basic understanding of how it works, but I am always surprised by the big bill each month. What gets me every time is that in addition to the regular fee for the egress traffic, you are also paying for the traffic being used on the cloud services; i.e. higher usage of cloud services equals higher billing.
This could be a huge wake-up call for projects in their infancy because if the extra fees are already starting to add up as your traffic rises, your budget could be in trouble. The extra problem is that the specifics of the costs associated with these traffic increases are not broken down or well explained. Everything is lumped under one huge item called NAT gateway. What’s the traffic about? Who knows, but god forbid you not to pay.
Dissecting Data Usage
Let’s take a small detour. To better understand our overall Kubernetes costs, our team decided to run an audit tool on Kubernetes so that our various departments could assume responsibility for their billable CPU and memory reservations. We started to monitor our Kubernetes usage, planning to use VMWare’s Cloud Health to collect the data, create a dashboard based on the Kubernetes labels, and report the usage to teams reserving too much CPU or memory. Our nickname for this little project is Kostner (name courtesy of Tomáš Hejátko).
Our Cloud Health data was collected with a helm chart. This functions by gathering the Kubernetes reservations and pushing them to the Cloud Health itself. This is done as often as needed to avoid any blank space in the dashboard. Data is collected by querying EKS control plane public endpoint unless the private endpoint is enabled.
Now, let’s jump back to the main story. How did I find out about the helm chart being deployed? The NAT gateway bill grew twice as much as normal:
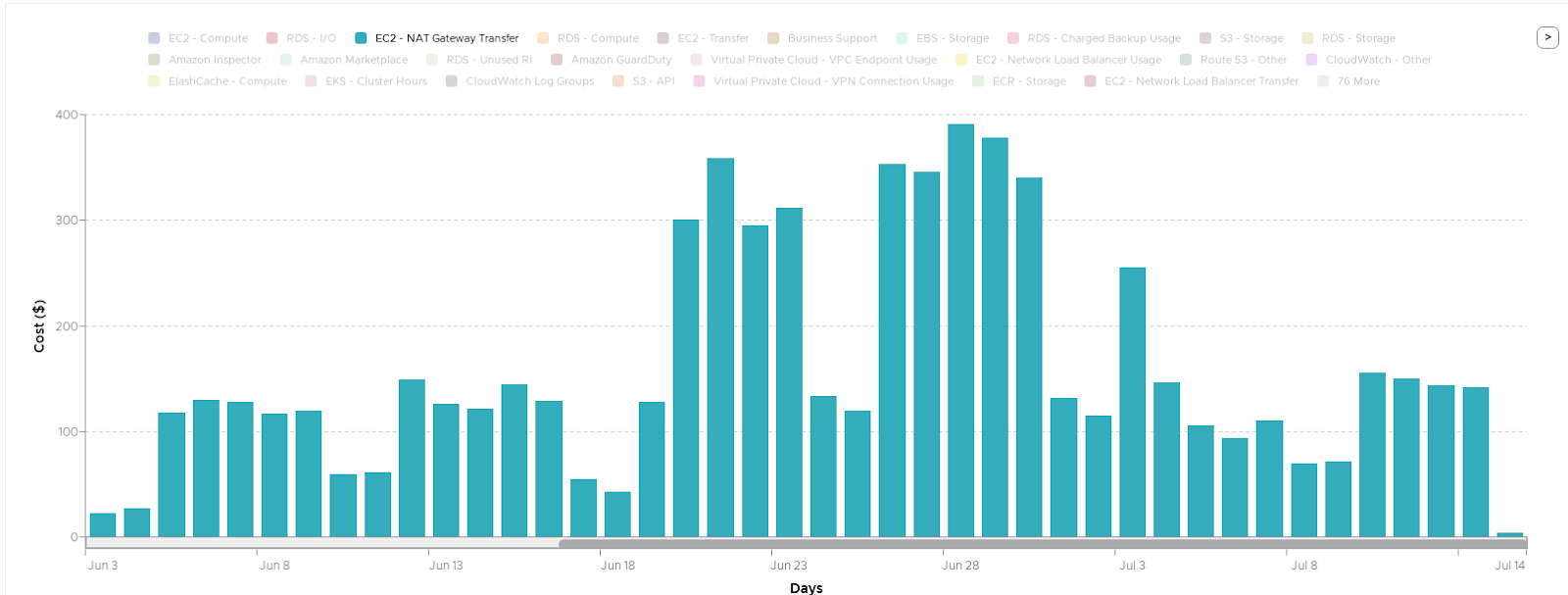
Finding the Needle in the Haystack
The problem is, not even the Cloud Health billing dashboard tells you specifically what that traffic increase is about. You are left with the cost and the resource ID, which is AWS ARN, not an answer about what action is directly responsible for the increased data usage and bill. However, that resource ID did lead me to the NAT gateway instance in the eu-west-1 region, where our dev environments live.
When I say dev environments, it’s not only dev and stage. Each of our developers can deploy an environment within the GitLab merge request containing the backend, frontend, and everything needed for development. I still think the ability to have these environments is one of the Golden geese of our company. Even so, finding the specific action that caused the increase is incredibly hard. But we pressed on and tried to find which one of these lines of EKS node pool egress traffic below was out of the ordinary:
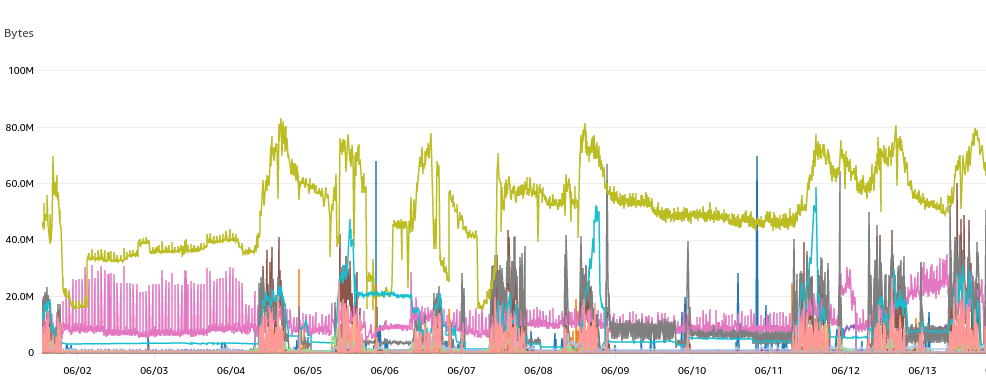
After minutes of picking through the data, I noticed the increase happened on 06/19. That was the day we installed the Cloud Health helm chart. And that was the bingo moment I was looking for!
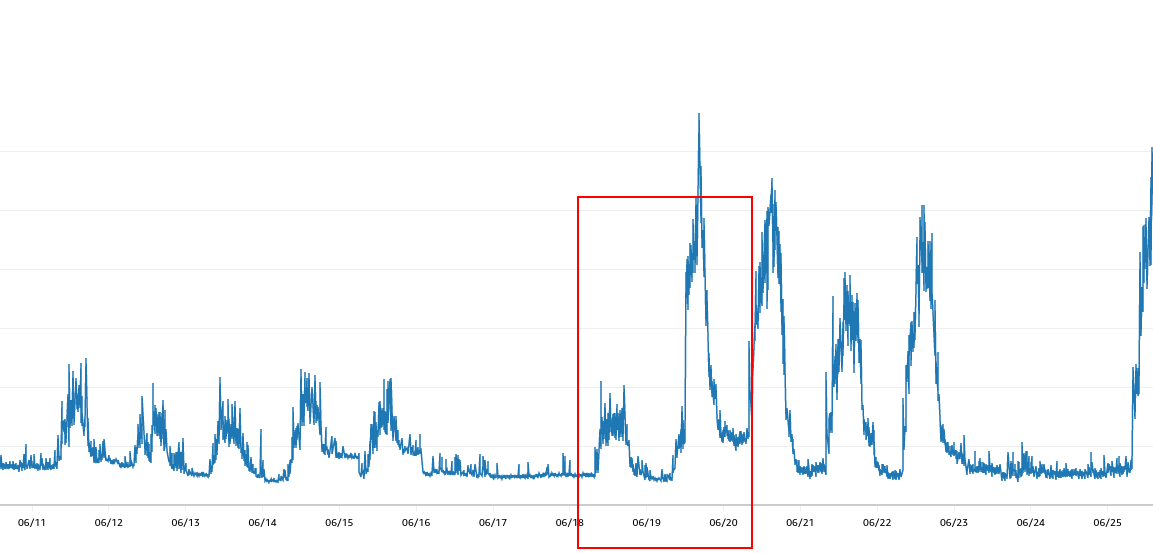
But why such a huge increase only for dev? Why not for CI clusters or production? As I was saying, any developer can have an environment. There are around 100 environments deployed each day. Plenty of them get suspended in 4 hours, and some run all the time. Anyway, each environment has around 100 pods. Each pod request for CPU and memory is collected by Cloud Health and pushed to the Cloud Health upstream servers. Hence, a lot of data is going through the NAT gateway to the EKS public endpoint to collect those pod requests.
Is This Really the Smoking Gun?
Unfortunately, no. To know what is really flowing in and out of your VPC, you need to check VPC flow logs. Since collecting them through the AWS CloudWatch can get expensive, we collect them in S3 buckets and store the data in case of a billing problem that needs to be queried later.
Let’s do an example of such a query to illustrate this. I’ll spare you a detailed explanation of how to import data to AWS Athena. Here is the average data for three days in the middle of a week for our example:
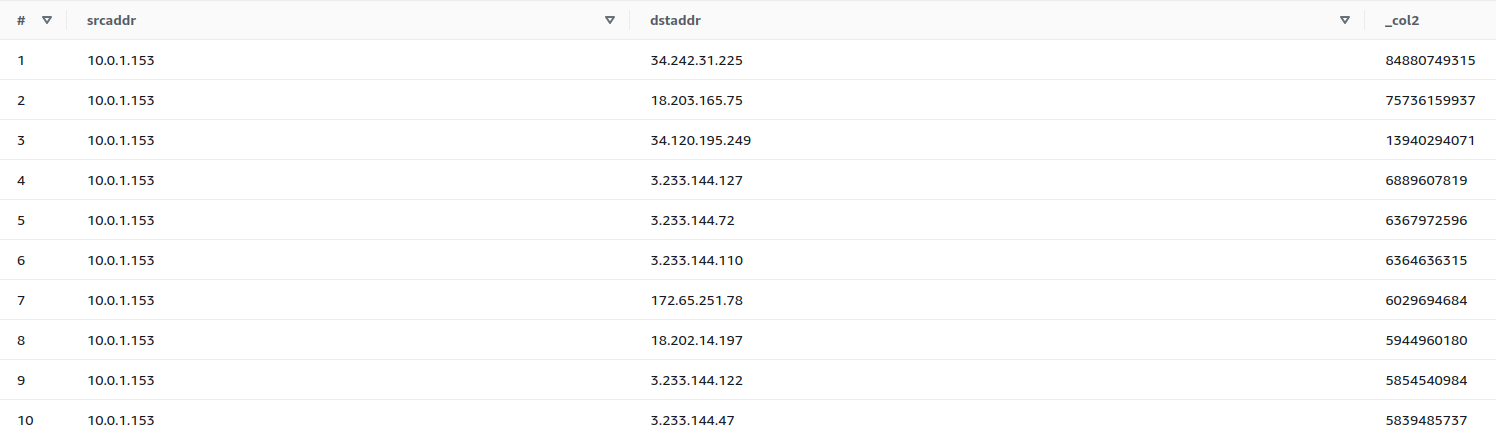
The _col2 column is just a bytes count of transmitted data. Now we know IP addresses 34.242.31.225, 18.203.165.75 and 34.120.195.249 are far from the next IP. Nice. But whose IP addresses are those? No worries, let’s use the host command:
$ host 18.203.165.75 75.165.203.18.in-addr.arpa domain name pointer ec2-18-203-165-75.eu-west-1.compute.amazonaws.com. $ host 34.242.31.225 225.31.242.34.in-addr.arpa domain name pointer ec2-34-242-31-225.eu-west-1.compute.amazonaws.com. $ host 34.120.195.249 249.195.120.34.in-addr.arpa domain name pointer 249.195.120.34.bc.googleusercontent.com.
Let’s ignore the IP for Google. How about those two other IP addresses? Which service is it? Is it AWS S3? Is it SQS? Well, I already spoiled it before. It’s the AWS EKS control plane IP address. How did I know? I just guessed. Sorry, I have no better explanation than that.
Wrap-Up
How to change the behaviour of the traffic going through a public network? There is a variable for that in the terraform module we use to deploy the EKS cluster. It enables a private endpoint for the control plane, meaning all the requests inside VPC flow directly to the control plane without leaving the AWS cloud.
Just be careful to add all the subnets or security groups to the cluster security group for the EKS cluster. If you miss any subnet, requests from the workload querying the control plane will start to timeout and not get through.
Following this investigation, our NAT gateway usage started to drop to the levels it displayed before deploying Cloud Health Kubernetes integration, and everything was alright again. Now we’re living happily ever after . . . until another service requires a private endpoint.
Like the YouTubers say, like and subscribe to read more about our escapades.